




Six months with AWS 15 October 2018
When I started with Ecogy Energy I was given the flexibility to use whatever technology I saw fit to develop the Asset Management platform. For me this was a golden opportunity to embrace AWS and serverless; what follows is an outline of the technologies used so far and my thoughts on where they excelled and where they were more troublesome than expected.
While the use of AWS services has been extensive I’ve only touched a small part of what they have on offer:
- API Gateway
- Lambda
- S3
- Route 53
- Cloud Front
- AWS Certificate Manager
- AWS Secret Manager
- DynamoDB
- Cognito
- Code Pipeline
- Code Build
- Cloud Watch
The basic architecture is pretty straightforwards, two HTML applications (one using Mithril, the other React) are hosted in S3 where Route53 and CloudFront make them accessible to the world via user friendly URLs. Both these applications talk to a single API that is deployed using API Gateway and backed by a number of serverless services that deploy NodeJS Lambda functions; these communicate with third party services via Restless APIs and make use of the AWS SDK to connect to AWS services.
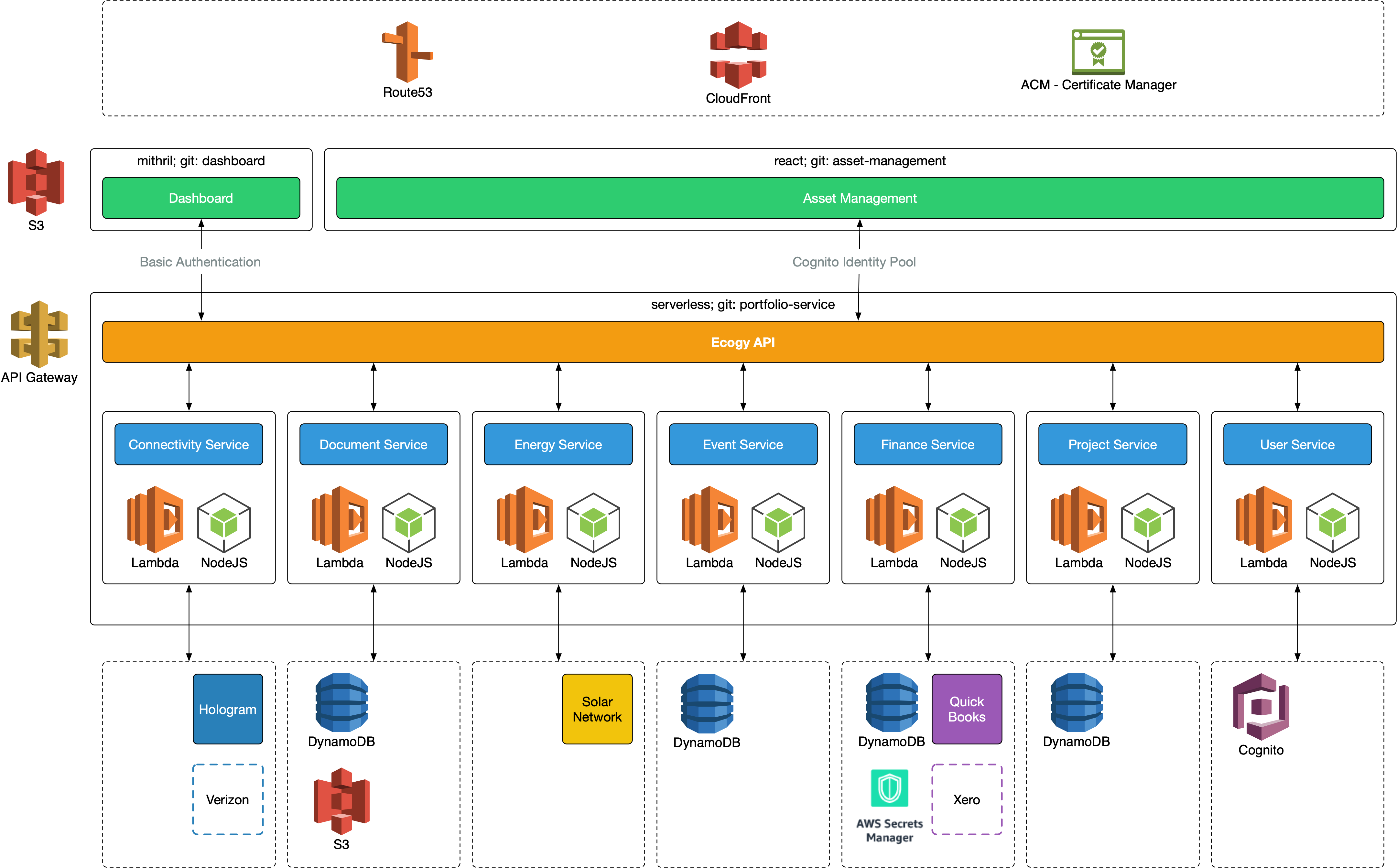
Front End Applications
The front end applications are straight HTML/Javascript applications that contain as little logic as possible, relying almost entirely on the API to provide the business logic and connect to third party and AWS services.
Because of this serving the application via EC2 instances, Kubernetes or any CPU based service would be pointless; we just need to deliver the HTML, CSS and JavaScript to the browser and AWS offers a service that seems ideal for this. S3 (Simple Storage Service) allows you to create buckets of content and one of the offerings is serving the content as a static website. Where this becomes tricky is when you want to provide secure access to your site over https. At this point you’re required to set up CloudFront and deal with some not so obvious gotchas that I’ve already covered.
Serverless
I chose serverless to manage and deploy my API Gateway and Lambda functions. This allows me to write a simple yaml file that is then used to generate and deploy a Cloud Formation template using the AWS SDK. It supports deploying to different stages (I’ve set up ones for development, testing and production) without the verbosity that Cloud Formation can bring.
Cloud Formation has a limit of 200 resources per template, something that I hit after a month or two of development, so I had to break up my serverless configuration into multiple services. It was getting to a point where this was becoming a necessity in any case and has the added benefit of breaking these services up into self contained units. There are only a few cross dependencies between them and the ones that exist are dealt with by calling Lambda functions provided by the other services where necessary.
To do this I have a base serverless configuration that deploys the shared API Gateway resources directly. Care does have to be taken here however; if you don’t put a shared resource in the correct place it can bite you later on down the road as the only way to get it back is to delete the deployed service entirely so that the resource can be moved into the more appropriate location.
One negative side affect of using serverless is that it essentially rules out the use of Cloud 9, the cloud based IDE that AWS provide and that allows realtime debugging of deployed Lambda functions.
Lambda
I’m a big fan of Lambda, it makes it easy to separate concerns, quickly deploy changes and there is no need to set up and keep a server running to execute your code. We have a light load currently and are still happily in the free tier.
So far for me the biggest issue has been trying to debug deployed code. Serverless allows me to execute and test functions locally which is great, but I rely on printing out useful information to the console and haven’t found a way to debug the functions directly. There are ways it can be done but I’ve yet to find one that is easy to set up and configure; though I must admit that I haven’t come across the need or had the time to dig into this too deeply.
One unexpected limitation I’ve encountered is threading. This is partly down to the way that my functions are designed, they retrieve content from numerous endpoints then process it. This can result in a bunch of responses coming back around the same time then being processed sequentially. I tried adding threading to my function, which worked handily locally but was much slower when deployed; I’m not sure if this was due to not having enough resources assigned to the function or if Lambda just didn’t like the attempt to start multiple threads. In any case I believe the simplest and most appropriate option would be to break the existing function into smaller Lambda functions and call them for each endpoint instead of trying to handle them all in the one functions.
Cloud Formation
While almost everything is being deployed using Cloud Formation via Serverless, there were some resources I set up manually at the start that I now wish I’d set up and deployed using code, specifically the Cognito User Group and Identity Pool. There’s nothing to stop this being done of course but there’s the risk of failing to copy everything properly and there are higher priorities. Next time I’ll make sure to do this from the start.
DynamoDB
I was excited to use DynamoDB, I’ve never had the chance to properly play with a NoSQL database before and it seemed like a natural fit for our needs; for the most part it’s been great as well but I have come across a number of limitations that would make me think seriously before committing to it in another project.
One of the great things about relational databases is, well, the relationships. It’s a flexible way of storing data that will typically support the data being used in a multitude of ways. With DynamoDB you’re a lot more limited in your options, if your requirements change significantly there’s a good chance you’ll have a serious amount of work on your hands to rework your data model to meet your new requirements. It requires a different way of thinking, something that AWS call out in their documentation, but sometimes it feels like you’re working very hard to do solve a problem that would be trivial in a relational database.
The main assets that I’m storing have a natural hierarchical relationship, something that I assumed would be easy to handle in DynamoDB. Certainly storing the objects was easy, the child objects are simply another property. Things got more complex when I wanted to limit the content returned using projections, it turns out that nested objects aren’t supported so to do this I would have to retrieve the whole child object property then filter out the pieces that I didn’t want. This also of course increases the size of the returned object with data that I don’t want in a particular request increasing the cost of the call.
I was also frustrated to find at one point that properties that are part of the key can’t be included in the filter expression. I do understand the reason why they do this, you should use it as part of the condition to limit the data returned; in my case I’ve ended up having to make numerous DynamoDB requests because of this rather than a single one, to filter out a small subset of data that I don’t want. The other option here of course would be to make a single call and filter out the data I don’t want myself.
Cognito
I have a bit of a mixed opinion of Cognito. It was much more complicated to set up than I expected and not as flexible or extendable as what I had in mind. However it does provide you with an out of the box solution for creating user accounts and dealing with Authentication, especially helpful with controlling access to the API Gateway which supports Cognito as an easily configurable authentication method.
I do wish I’d embraced Amplify and all it offers more. It has a lot of features that I don’t need but I’ve ended up relying heavily on it whereas I originally wanted to keep more control. The end result is that I’ve implemented solutions that Amplify would have solved directly but it was hard to determine that from reading the documentation originally as I got overwhelmed by the functionality that I didn’t need. Next time I suspect I may just make use of the Amplify library and functionality.
CI/CD
I’ve set up a basic Continuous Integration and Continuous Delivery pipeline using AWS Code Pipeline and Code Build.
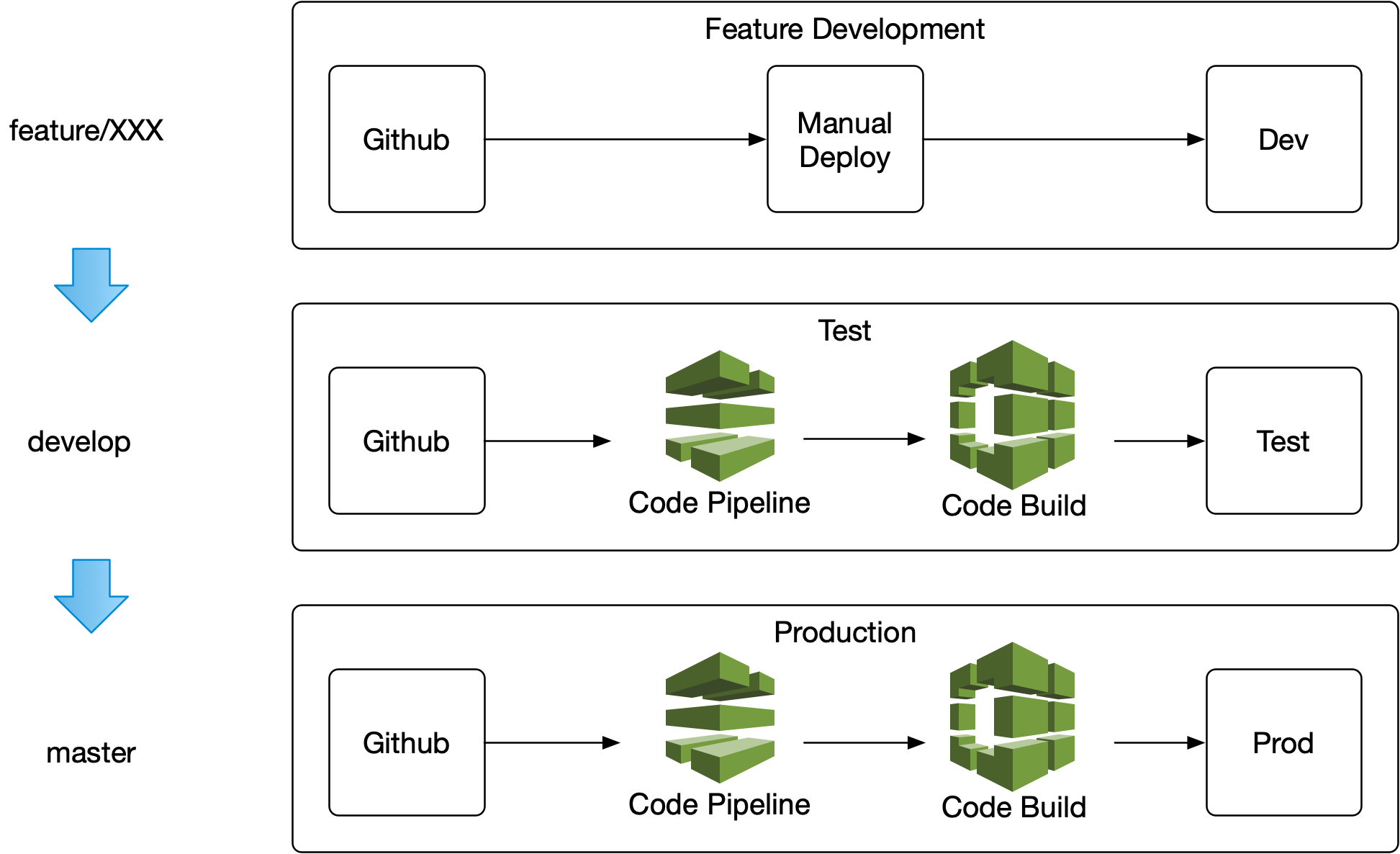
Development is done on feature branches, testing locally and deployed to the shared development stage for integrated testing. Once I’m happy with it I merge the feature branch into the develop branch and Code Pipeline picks up the changes and kicks off Code Build.
Code Build gets the latest code for the branch from Github and compiles the application. The test cases are run against the compiled code and if they fail an email is sent to support list with a link to the failed build. If the build succeeds, the Code Build script either copies the application to S3, or in the case of the API runs the serverless deploy commands.
Once we’re happy with what’s been deployed to test I merge develop into master and the same process is run for the production environments.
One surprise I found was that as I’d used version 0.1 of the buildspec.yml, it runs each command in its own shell which is not how I’m used to scripting. Version 0.2 on the other hand will execute the commands more conventionally.
Conclusion
Having come from the pretty archaic world of ATG which hasn’t been bleeding edge in a very long time and from working on projects for large eCommerce retailers with limited opportunities to use new technologies, jumping into the world of AWS full time has been immensely refreshing. So many of the hoops you always had to jump through have been removed especially with serverless. If there’s a common problem it’s typically already been solved and while there’s always limitations and room for improvement the rate that these and new features and services are rolled out is impressive. I’m more than happy with the choice of AWS and the rich community that supports it and look forward to exploring more of what’s on offer as the opportunities come up.